
个体患者数据荟萃分析(IPDMA)是一种强大的分析手段,有时能揭示出在汇总数据或试验层面荟萃分析中难以洞察的信息。那么,在探讨他汀类药物对心血管疾病(CVD)一级预防的作用时,这些分析是否就是最优之选呢?答案或许并非如此。
首先,根据CTT的数据,服用他汀类药物后,低密度脂蛋白胆固醇(LDL-C)的平均降幅大约为1mmol/L。这一估算主要基于一年时间范围内的观察,并且涵盖了初级和次级预防试验的数据。而美国预防服务工作组(USPSTF)在2022年进行的系统综述和荟萃分析(SRMA)中,并未提及LDL-C的变化情况。不过,2013年考克伦(Cochrane)对他汀类药物一级预防的综述却发现,LDL-C的降幅与此相近,为1(95% CI,0.85至1.16)mmol/L。此外,值得注意的是,2016年发表的一项重要试验——HOPE-3,其报告显示平均LDL-C降幅约为0.89mmol/L。
胆固醇治疗试验者协会(CTT)的分析模型估算了每降低1mmol/L低密度脂蛋白胆固醇(LDL-C)时心血管(CV)风险降低的情况,结果显示每降低1mmol/L的LDL-C,风险比(RR)为0.75(95%置信区间为0.71至0.80)。然而,当LDL-C降低幅度超过1mmol/L时,这一估计值的可靠性又将如何呢?让我们进一步探究CTT的分析结果:
简而言之,通过数据可视化,我们可以获得更加细致的观察视角。尽管上述RR和95%置信区间看似十分确定,但如果我们仔细观察各个试验的具体数据:
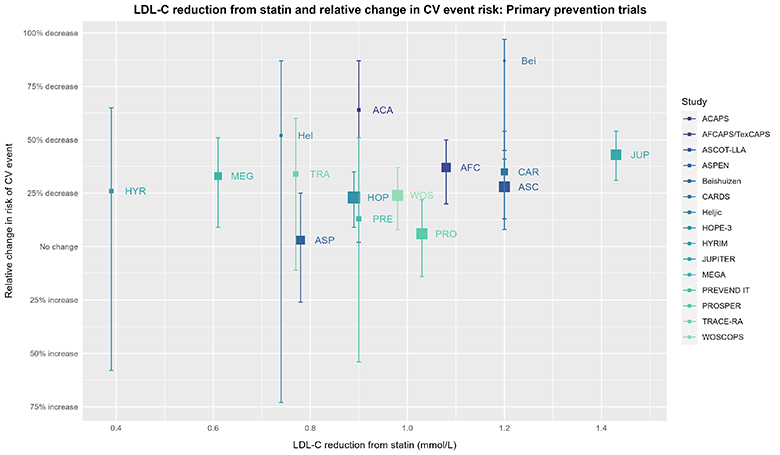
图中单个试验的方块大小与效应估计值的方差成反比(效应估计值越精确,方块越大)。试验的相对效应估计值来自美国预防服务工作组(USPSTF)的系统综述和荟萃分析(SRMA)。而相应LDL-C降低的数值(仅在CTT的IPDMA中考虑了一年时间范围,而USPSTF的SRMA并未考虑)则来源于Byrne 2022的研究,并且已经与Silverman 2016的研究进行了交叉核对。对于任何大于0.01mmol/L的差异,我们都通过查阅原始论文来解决。至于未包含在Byrne 2022或Silverman 2016研究中的试验(由于纳入/排除标准),其LDL-C降低数值则来源于考克伦综述或对原始论文的查阅。本图表采用R(4.3.0)中的ggplot2(3.4.2)绘制而成。
现在,如果有人问你是否注意到了上述数据中的某种规律,以及这种规律是什么,你会怎么回答呢?
为了继续我们的思想实验,现在让我们再次查看这张图表,但这次我们要加入胆固醇治疗试验者协会(CTT)的估计值。在查看接下来的可视化图表时,请思考以下问题:CTT的估计值在多大程度上反映了基础试验数据的真实情况?换句话说,虽然我们可以“画线”贯穿任何数据,但CTT的估计值在证明剂量-反应效应方面到底有多大说服力呢?在思考这个问题时,请回想一下你当初查看没有显示CTT估计值的“原始”图表时的想法。
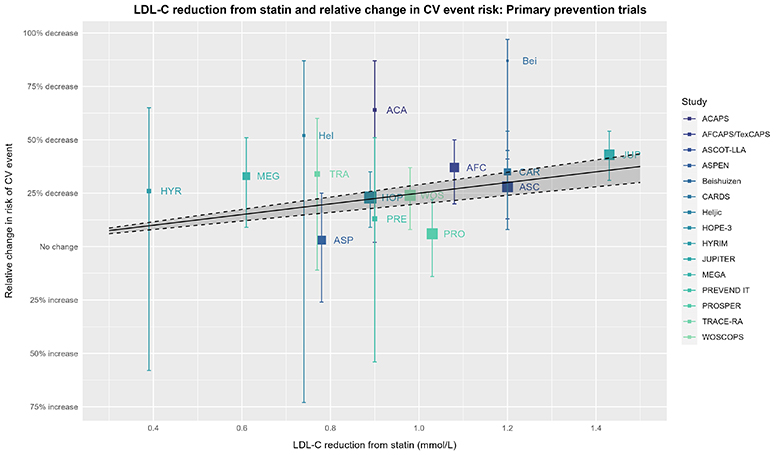
上述图表的说明同样适用于此图。实线、虚线和阴影区域均基于2019年胆固醇治疗试验者协会(CTT)个体患者数据荟萃分析(IPDMA)的结果,展示了每降低1mmol/L(≈38.7 mg/dL)低密度脂蛋白胆固醇(LDL-C)时,对应的风险比(RR)为0.75(95%置信区间为0.71至0.80),即风险降低率(RRR)为25%(95%置信区间为20%至29%)的预期效应估计。
为了继续深入探索,我们可以利用试验层面的数据(以LDL-C降低为协变量)进行元回归分析,进一步分析LDL-C降低与心血管(CV)风险相对变化之间的关系:
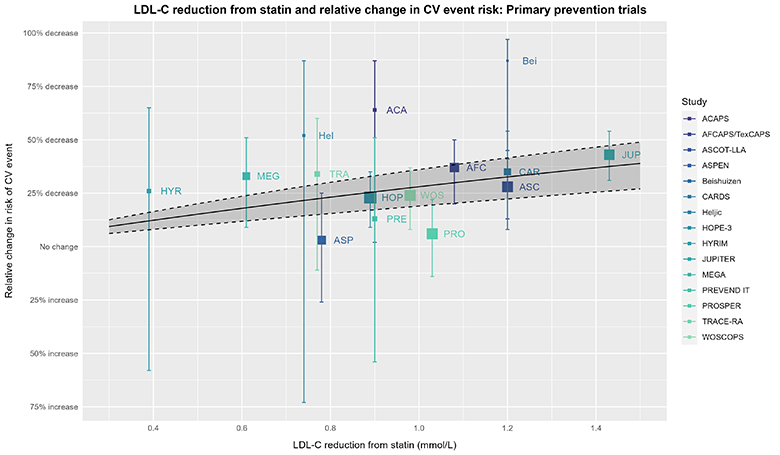
除了实线、虚线和阴影区域所表示的基于试验层面数据的元回归及其95%置信区间(使用了meta [6.2-1]和metafor [4.2-0]软件包)外,上述图表的说明同样适用于此图。由于本分析与胆固醇治疗试验者协会(CTT)的个体患者数据荟萃分析(IPDMA)存在差异,因此该分析得出的较宽的95%置信区间并不令人意外。
对于热爱统计学的读者来说,无论是CTT分析还是上述基于试验层面数据的元回归,都强制将模型截距设为零点,这意味着如果LDL-C的降低值为零,那么心血管(CV)风险的降低值也将为零。换句话说,这两种分析都假设他汀类药物的功效完全是通过降低LDL-C来实现的。基于我们已知的LDL-C在心血管风险中的作用以及他汀类药物对LDL-C的影响,这一假设似乎是合理的。然而,他汀类药物还具有独立于降低LDL-C的多效性作用(例如,Davignon 2004、Ray 2005、Ridker 2008、Oesterle 2017的研究所示),因此,仅仅假设他汀类药物的功效完全通过降低LDL-C来实现可能过于简化问题。虽然我们无法看到没有这一假设的CTT分析,但我们可以考虑不强制截距为零点的同一元回归,以此继续我们的思想实验:
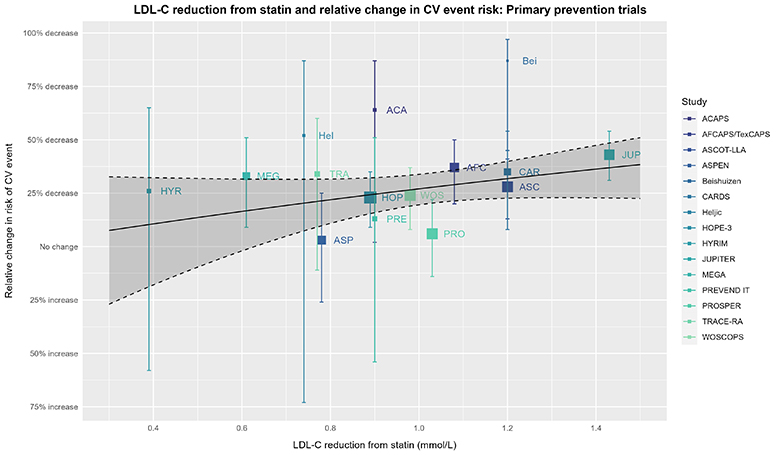
上述图表的说明同样适用于此图。
关于元回归的注意事项
这些元回归看起来或许颇具吸引力,但在推论上,元回归有时可能会产生误导(请允许我使用这里的双关语),因此,上述例子更多应被视为我们思想实验中的探索性内容。元回归通常存在功率不足的问题,它总是基于观察性的(Deeks 2019, Riley 2021),如果不仔细进行并慎重考虑,可能会导致误解。
一个关键问题在于,当通过基于跨研究汇总数据的协变量进行元回归时,我们试图估计个体层面的治疗与协变量之间的交互作用。然而,这种协变量通常在同一研究的参与者之间会存在变化,这种情况很可能导致汇总偏差(有时也被称作生态谬误/偏差)。这种方式的元回归甚至被批评为“不理智的”(Fisher 2017, Riley 2021)。
上述元回归确实存在这样的问题。此外,与协变量是任何给定患者治疗前可以识别的因素不同,它是一个治疗后、组间的变量(稍后我们会详细讨论这一点)。
那么,CTT分析是否也采用了相同的方法呢?简而言之,是的。尽管他们拥有个体患者的数据,但很明显,他们在计算LDL-C的差异时使用了跨研究的汇总数据:
对于主要的LDL加权元分析,我们设定某一试验中接受积极治疗和接受对照治疗的患者在一年后的LDL胆固醇(mmol/L)平均绝对差异为w。接着,我们将该试验的对数秩(o-e)乘以权重w,方差乘以w的平方,然后将每个试验的这些加权值相加,得出加权总和(GW)及其方差(VW)。最后,通过计算exp(GW/VW)的值,我们得到每降低1.0 mmol/L的LDL胆固醇时,事件率比(RR)的一步加权估计值。
个体患者数据实际上无法对感兴趣的协变量提供实质性的“帮助”,因为CTT分析关注的是治疗组与对照组之间LDL-C的差异。按照定义,组间差异无法针对单个患者进行评估,因为每位患者只能从基线开始经历LDL-C的变化,这必然包含了因干预措施导致的LDL-C变化以及随时间发生的其他所有因素(例如生活方式的改变)。这正是组内分析在尝试理解干预措施影响时如此棘手的关键原因(因此,即使CTT采用了每位患者从基线开始的变化数据,情况也不会有所改善)。
所以,事情变得相当复杂。CTT对心血管疾病风险降低的预测并非绝对可靠,尤其是如果我们不打算将置信区间的意义纳入临床决策中时。这并不仅仅是吹毛求疵的完美主义。迄今为止的考量引发了关于每降低1 mmol/L的LDL-C时心血管疾病风险降低建模的疑问,以及关于这种效应是否完全由此介导的假设。
本文内容并不否认LDL-C在不良心血管事件病理生理学中的作用,也不排除降低LDL-C在初级预防中具有预测心血管疾病风险降低能力的可能性。然而,LDL-C只是一个替代标志物,多年来,许多专家(例如Hayward 2012, Hofer 2016, Mayer 2016, Krumholz 2017)都强调应重点关注与患者相关的结局。Krumholz在2017年的总结非常到位:
“除了极端情况,决策应基于风险降低,而非胆固醇水平。基于证据的降脂药物似乎能够降低风险,即使患者的初始LDL水平较低;它们本质上是降低风险的药物。”
此外,还有更多因素需要考虑。
意向治疗原则又该如何考虑呢?
在利用CTT分析时,一个关键的障碍在于他们选择以每降低1 mmol/L的LDL-C为基准来建模效果。这种选择实际上打破了意向治疗原则(ITT),因为问题的焦点不再是“如果我开出这种他汀类药物,你能在降低心血管疾病风险方面获得多少益处?”(这正是试验所探讨的核心),而是转向了“如果你服用这种他汀类药物,并且药效显著,你的用药依从性足够高,最终使得你的LDL-C降低了X量,那么你在降低心血管疾病风险方面又能获得多少益处?”。这两者显然是不同的问题。
举例来说,对于用药依从性更高的人来说,他们的LDL-C降低幅度可能更大,或者在心血管疾病风险方面表现更好,这并不奇怪。毕竟,他汀类药物在规律服用时效果最佳。但与那些用药依从性较差的人相比,依从性高的人往往在其他方面也存在差异,这些差异共同导致了一个更有利的预后。这种“用药依从性倾向”既可能与LDL-C的降低程度有关,也可能与心血管疾病风险有关,这使得情况变得复杂。
忽视这一推论障碍显然是不明智的,甚至在与患者讨论时,我们不得不强调他汀类药物的益处是建立在达到一定程度的LDL-C降低的基础上的,这无疑增加了沟通的复杂性。尽管对于低、中、高强度他汀类药物,存在关于LDL-C相对降低幅度的普遍预期,但这些预期值基本上是平均值。总的来说,CTT的估计打破了ITT原则,它依赖于达到一定程度的LDL-C降低(而这并非试验所考察的内容),并假设所有效果都是通过降低LDL-C来实现的。更重要的是,叠加预期的LDL-C降低会进一步增加不确定性(即便不考虑其他因素,至少也为随机误差提供了空间)。
因此,在利用CTT IPDMAs来评估他汀类药物在心血管疾病一级预防中的疗效时,我们尤其需要谨慎对待,特别是在临床决策过程中。那么,USPSTF SRMA又能为我们提供哪些新的启示呢?敬请期待下周的分享!